Prepare
PDF vs. Markdown: A Hard-Data Case Study in AI File Efficiency
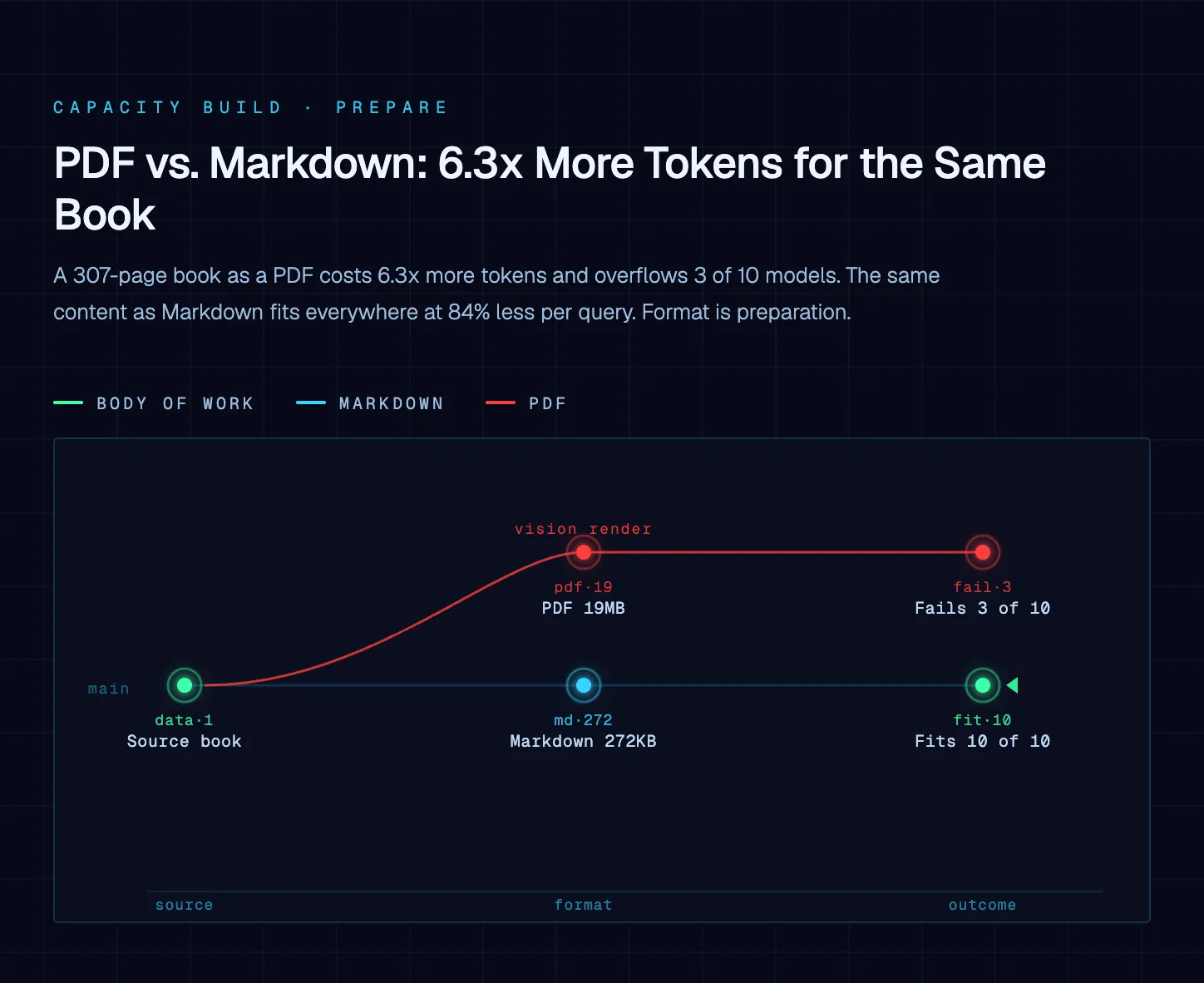
The same 307-page book as a PDF and as Markdown, measured: tokens consumed, what the AI can see, and what each session costs. The findings are numbers.
Document: A 307-page business management book
Analysis Date: May 2026
Methodology: Direct file measurement, token estimation using industry-standard approximations (3.75 chars/token average across providers), live API pricing sourced from official documentation, context window data from provider specifications.
The Core Argument
AI models don’t read documents the way humans do. They don’t open a file, skim a few pages, and land on the answer. They process every token of input on every query – and the format of that input determines how many tokens get consumed, what the AI can actually see, and what that session costs.
This case study measures what happens when you take the same document – a 307-page business management book – and compare it as a PDF versus a Markdown file. The findings are numbers.
Section 1: The Files
Hard File Data
| Metric | Markdown | Ratio | |
|---|---|---|---|
| File size | 20,196,588 bytes (19.26 MB) | 278,066 bytes (271.5 KB) | 72.6x larger |
| Pages / Lines | 307 pages | 7,158 lines | – |
| Characters (text content) | 276,127 (extracted) | 274,794 | 1.005 (near-identical) |
| Words | ~45,437 (extracted) | 46,428 | ~1.02 |
These two files contain essentially the same text. The fidelity ratio of extracted PDF text to Markdown text is 1.005 – a 0.5% difference attributable to minor formatting characters and whitespace normalization. The information content is the same. The delivery mechanism is radically different.
The PDF is 72.6 times larger than the Markdown file. That 20MB includes fonts, vector graphics, layout metadata, embedded images, and binary overhead that carries zero informational value for an AI model performing text-based reasoning. The Markdown file strips all of that away and delivers the same content in 272 kilobytes.
Section 2: Tokens – The Currency of AI
What Tokens Are
AI models don’t read files. They read tokens – chunks of text roughly equivalent to three to four characters each. Every token you send to a model costs money. Every token also consumes a portion of the model’s “context window,” which is the maximum amount of information it can hold in working memory at one time.
Industry-standard token estimation:
- ~3.5 characters per token (Anthropic/Claude)
- ~4.0 characters per token (OpenAI/GPT)
- Average used here: 3.75 characters per token
For PDF files, the situation is more complex. When you upload a PDF to an AI tool, the model processes it in one of two ways: text extraction (if the PDF has a clean text layer) or vision rendering (treating each page as an image). When processed as images – the default for many AI tools and the method required for scanned, image-heavy, or visually formatted PDFs – each page costs approximately 1,500 tokens regardless of how much text is actually on that page.
Token Count Comparison
| Format | Estimated Tokens | Method |
|---|---|---|
| Markdown | 73,278 | Character-based calculation (~3.75 chars/token) |
| PDF (vision processing) | 460,500 | 307 pages × 1,500 tokens/page |
Token ratio: 6.3x
To send this book to an AI model as a Markdown file costs approximately 73,278 input tokens. As a PDF processed through vision rendering, the same book costs approximately 460,500 input tokens. That is 6.3 times more tokens for the exact same informational content.
This ratio is the cost multiplier for every single query you run against this file.¹
Section 3: Context Window – What Fits and What Doesn’t
The context window is the hard ceiling of what any AI model can see at once. A document that exceeds the context window cannot be processed in a single query – it must be chunked, split, or summarized, introducing friction and degrading response quality.
Context Window Analysis: This Book
| Model | Context Window | Markdown (73K tokens) | PDF (460K tokens) | PDF Processable? |
|---|---|---|---|---|
| Claude Haiku 4.5 | 200,000 | 36.6% of window | 230.3% | ✗ Fails |
| Claude Sonnet 4.6 | 1,000,000 | 7.3% of window | 46.1% of window | ✓ Yes |
| Claude Opus 4.6 | 1,000,000 | 7.3% of window | 46.1% of window | ✓ Yes |
| GPT-4o (legacy) | 128,000 | 57.2% of window | 360% | ✗ Fails |
| GPT-4.1 Mini | 1,000,000 | 7.3% of window | 46.1% of window | ✓ Yes |
| GPT-4.1 | 1,000,000 | 7.3% of window | 46.1% of window | ✓ Yes |
| o3 (OpenAI reasoning) | 200,000 | 36.6% of window | 230.3% | ✗ Fails |
| Gemini 2.5 Flash | 1,000,000 | 7.3% of window | 46.1% of window | ✓ Yes |
| Gemini 2.5 Pro | 1,000,000 | 7.3% of window | 46.1%* | ✓ Yes* |
| Gemini 3 Pro | 1,000,000 | 7.3% of window | 46.1%* | ✓ Yes* |
*Gemini tiers: Gemini 2.5 Pro and 3 Pro use tiered pricing where prompts exceeding 200K tokens are billed at 2x the standard rate – all tokens, not just the overflow. See Section 4 for cost implications.
Key Results
The Markdown file fits inside every current production AI model without issue.
The PDF exceeds the context window of three major models entirely:
-
GPT-4o (128K window) – the most widely used ChatGPT model among everyday users. A 307-page book as a PDF consumes 360% of this model’s context window. You cannot send this document to ChatGPT using GPT-4o in a single query. It will fail, be truncated, or require manual chunking.
-
Claude Haiku 4.5 (200K window) – Anthropic’s fastest and most affordable model. The PDF requires 230% of its available window. Same result.
-
OpenAI o3 (200K window) – OpenAI’s advanced reasoning model. Also fails.
A small business person who uploads this PDF to standard ChatGPT, selects GPT-4o, and asks a question about Chapter 3 is asking a model that cannot hold the full document in memory. They will get a partial answer, a truncated analysis, or an error – and they will likely not understand why.
The Markdown version of the same book uses 7.3% of the context window on the models that support 1M tokens, and 36.6% on the 200K models. It fits everywhere, cleanly, with room left for the conversation.
Section 4: Cost Analysis
Current AI Model Pricing (May 2026)
Input token pricing per 1 million tokens:
| Provider | Model | Input Cost/1M | Context Window |
|---|---|---|---|
| Anthropic | Claude Haiku 4.5 | $1.00 | 200K |
| Claude Sonnet 4.6 | $3.00 | 1M | |
| Claude Opus 4.6 | $5.00 | 1M | |
| OpenAI | GPT-4.1 Mini | $0.40 | 1M |
| GPT-4o (legacy) | $2.50 | 128K | |
| GPT-4.1 | $2.00 | 1M | |
| o3 | $15.00 | 200K | |
| Gemini 2.5 Flash | $0.30 | 1M | |
| Gemini 2.5 Pro | $1.25 (≤200K) / $2.50 (>200K) | 1M | |
| Gemini 3 Pro | $2.00 (≤200K) / $4.00 (>200K) | 1M |
Sources: Anthropic API documentation, OpenAI API pricing, Google AI for Developers pricing page – all verified April–May 2026.
Cost Per Single Query (Input Tokens Only)
| Model | Markdown | Cost Ratio | |
|---|---|---|---|
| Claude Haiku 4.5 | $0.073 | N/A – PDF exceeds window | – |
| Claude Sonnet 4.6 | $0.220 | $1.382 | 6.3x |
| Claude Opus 4.6 | $0.366 | $2.303 | 6.3x |
| GPT-4.1 Mini | $0.029 | $0.184 | 6.3x |
| GPT-4o (legacy) | $0.183 | N/A – PDF exceeds window | – |
| GPT-4.1 | $0.147 | $0.921 | 6.3x |
| o3 | $1.099 | N/A – PDF exceeds window | – |
| Gemini 2.5 Flash | $0.022 | $0.138 | 6.3x |
| Gemini 2.5 Pro | $0.092 | $1.151† | 12.6x |
| Gemini 3 Pro | $0.147 | $1.842† | 12.6x |
†Gemini’s tiered pricing structure charges all tokens at the higher rate when the total input exceeds 200K. The PDF (460K tokens) crosses this threshold, triggering 2x pricing on every single input token. The Markdown file (73K tokens) stays below the threshold and is never subject to this surcharge.
Monthly Cost at Scale – Claude Sonnet 4.6
Assumption: Each query sends the full document as context (standard practice for document-grounded Q&A)
| Queries/Month | Markdown Total | PDF Total | Monthly Savings | Cost Reduction |
|---|---|---|---|---|
| 1 | $0.22 | $1.38 | $1.16 | 84% |
| 10 | $2.20 | $13.81 | $11.62 | 84% |
| 50 | $10.99 | $69.08 | $58.08 | 84% |
| 100 | $21.98 | $138.15 | $116.17 | 84% |
| 200 | $43.97 | $276.30 | $232.33 | 84% |
| 500 | $109.92 | $690.75 | $580.83 | 84% |
The cost reduction is consistent at 84% because the relationship is a fixed ratio. Every time you query the full document, a PDF costs 6.3x more. That ratio doesn’t improve with scale – it compounds.
At 50 queries per month (a light but realistic workload for someone actively using their document as a knowledge base), the Markdown file saves $58 per month over the PDF. At 200 queries per month – more typical for a business actively running document-grounded workflows – it saves $232 per month.
Section 5: Efficacy and Query Quality
Beyond cost, the format of a document affects how well an AI model can work with it. This is where Markdown’s advantage compounds.
Structural Clarity
Markdown preserves semantic structure through headers, subheadings, and consistent formatting. When a model reads this book as a Markdown file, it understands:
- This is a chapter title
- This is a section header
- This is body text
- This is a list item
PDF text extraction flattens or disrupts that hierarchy. Page numbers are embedded as text strings (# 19, # 20) that appear mid-paragraph in the extracted output, creating noise the model must work around. Cross-page content is concatenated without clear structural signals, forcing the model to infer boundaries that Markdown states explicitly.
Practical effect: When you ask “What are the four main action concepts in Part Two?”, a Markdown file lets the model navigate a clean heading structure. A PDF requires the model to reconstruct the organizational logic from unstructured text.
Reliability Across Models
Markdown is a universal plaintext format. Every model processes it identically. There is no binary parsing, no font table, no embedded object resolution. The file is exactly what it says it is on every platform, every time.
PDF processing behavior varies by:
- Provider (Claude processes PDFs differently than GPT-4o)
- Document version (scanned vs. text-layer PDFs produce radically different results)
- Model settings (vision mode vs. text extraction mode)
- Document complexity (tables, multi-column layouts, footnotes, images)
A Markdown file produces consistent, predictable behavior. A PDF introduces variability that degrades at scale.
Storage in AI Projects
Both Claude and ChatGPT offer “Projects” features where you can store files for persistent access across conversations. Storage limits are practical constraints.
| Format | File Size | In a 100MB Project |
|---|---|---|
| 19.26 MB | Fits 4 documents | |
| Markdown | 271.5 KB | Fits 367 documents |
The same 100MB project that holds 4 PDFs can hold 367 Markdown files.
That is the practical difference between building a workspace around one or two reference documents and building a comprehensive AI knowledge base across your entire business – SOPs, proposals, playbooks, reports, client materials, training guides, and reference documents, all loaded simultaneously, all queryable at once.
Maintainability
Markdown can be opened, edited, searched, version-controlled, and updated in any text editor. It works with every workflow tool. It can be split, merged, restructured, or converted without specialized software.
PDF content is fixed. Updating a paragraph in a PDF requires the original source file and software to regenerate it. Searching a PDF for text is approximate. Version-controlling a PDF means storing binary diffs.
Section 6: What This Means If You Have a Document Library
A single document tells part of the story. Most businesses don’t have one document – they have dozens or hundreds: SOPs, proposals, contracts, guides, training materials, reports, client-facing assets, internal playbooks. The question isn’t just what one PDF costs. It’s what a library of PDFs costs.
The Compound Effect
The cost ratios documented in this study are not one-time. They apply every time a file is sent to an AI model. If a small business owner queries their materials 50 times a month across 10 documents, the format of those documents determines not just one query cost – it determines the cumulative overhead of their AI practice.
| Documents | Queries/Month | Monthly Cost – PDF Library | Monthly Cost – Markdown Library | Annual Savings |
|---|---|---|---|---|
| 5 docs | 50/month | $345.38 | $54.97 | $3,485 |
| 10 docs | 50/month | $690.75 | $109.92 | $6,971 |
| 20 docs | 50/month | $1,381.50 | $219.84 | $13,941 |
Calculated at Claude Sonnet 4.6 pricing ($3.00/1M input tokens), 50 queries per month per document.
These numbers assume a best-case PDF scenario – clean, text-layer documents like the one tested here. For businesses whose document libraries include scanned files, branded presentations, multi-column reports, or image-heavy materials, the calculation is significantly worse.
When PDFs Get Harder to Process
This study tested a well-produced, text-layer PDF – an optimal case. Business document libraries include:
- Scanned documents and contracts: No readable text layer. Every page must be processed as a full image. Token costs multiply and extraction quality degrades.
- Branded presentations and decks: Heavy with images, charts, and visual layouts. Vision processing token costs climb sharply per page.
- Multi-column reports and whitepapers: Layout complexity disrupts text extraction, causing the model to misread the reading order and produce confused outputs.
- Locked or encrypted PDFs: Text extraction is blocked entirely, forcing vision-only processing regardless of model capability.
In these cases, the efficiency gap between PDF and Markdown widens substantially. A scanned 100-page contract may carry 10 to 20 times the token overhead of its Markdown equivalent. A brochure-style annual report with full-bleed images may be functionally impossible to query coherently as a PDF.
The Format Determines the Floor
For AI tools, format is a technical constraint that sets a floor on what is achievable. A business that has converted its core materials to Markdown has a different AI capability than one that hasn’t – not because the AI is different, but because the AI can see more, more clearly, at lower cost, across more models, simultaneously.
The prepared file is the activated file – ready to do its work in every session it enters.
The businesses that extract the most value from AI tools in the next five years will be the ones who understood early that the quality of AI output is inseparable from the quality of input – and that format is the first, most controllable variable in that equation.
Format is preparation. The PDF and the Markdown contain the same words – but only one is prepared for AI to use.
Section 7: Summary of Findings
Quantitative
| Metric | Finding |
|---|---|
| File size ratio | 72.6x (PDF is larger) |
| Token ratio | 6.3x (PDF consumes more) |
| Text fidelity loss | 0.5% (negligible) |
| Cost per query (Claude Sonnet 4.6) | 84% more expensive for PDF |
| Monthly savings at 50 queries | $58.08 (Markdown) |
| Monthly savings at 200 queries | $232.33 (Markdown) |
| Models where PDF fails entirely | 3 of 10 tested (GPT-4o, Haiku 4.5, o3) |
| Models where Markdown fits cleanly | 10 of 10 tested |
Qualitative
| Dimension | Markdown | |
|---|---|---|
| Structural clarity | Headers, hierarchy intact | Page numbers embedded as noise; layout collapsed |
| Processing consistency | Identical across all models | Varies by model, PDF type, rendering mode |
| Storage efficiency | 271.5 KB | 19.26 MB |
| Editability | Full – any text editor | Requires source file + software |
| Universal compatibility | Yes | Dependent on PDF parser quality |
| Context window risk | Zero on all tested models | Overflow failure on 3 of 10 |
Footnotes
¹ On PDF text extraction: If a PDF has a clean, machine-readable text layer, some AI tools can extract text directly and bypass vision rendering – in which case the PDF token count approaches the Markdown count. Three factors limit the practical significance of this: (1) this behavior is model-dependent and not guaranteed across tools or providers, (2) a large proportion of real-world business PDFs are scanned, image-heavy, or visually formatted and cannot use text extraction, and (3) even with clean text extraction, the PDF’s binary format carries parsing overhead that Markdown never requires. The 6.3x ratio reflects the standard consumer use case – a user uploading a PDF to Claude, ChatGPT, or Gemini without API-level configuration.
Appendix: Methodology Notes
File measurement: Direct file system byte counts and pypdf library page extraction. PDF character count obtained via text extraction from all 307 pages. Markdown character count obtained directly from raw file.
Token estimation: Using the industry-standard approximation of 3.75 characters per token (the midpoint of Anthropic’s stated 3.5 chars/token and OpenAI’s stated 4 chars/token). This is a widely-used approximation for cost estimation; actual token counts vary by content type, language, and model-specific tokenizer. The actual ratio between PDF and Markdown processing costs may vary, but the direction and order of magnitude are stable.
PDF vision processing rate: 1,500 tokens per page is the widely-cited industry standard for vision-rendered PDF pages at standard document resolution (8.5” × 11”, 72 DPI equivalent). Actual costs depend on page content density, resolution settings, and model.
Pricing sources: Anthropic API Pricing documentation (platform.claude.com), OpenAI API Pricing (openai.com/api/pricing), Google AI for Developers Pricing (ai.google.dev/gemini-api/docs/pricing) – all verified April–May 2026.
Context window data: Provider model specification pages. o3: 200K tokens (Azure OpenAI documentation). GPT-4o: 128K tokens (OpenAI documentation). Claude models: Anthropic documentation.
Want a Format Audit of Your Document Library?
Book a 30-minute AI Discovery Call where we audit the documents your business loads into AI most often – proposals, SOPs, reports, client materials – and identify which ones are bleeding tokens, which ones won’t fit, and which conversions would pay for themselves first. No deck, no pitch, no obligation.