Prepare
ChatGPT Knowledge Base: How a Content Archive Becomes a Working Asset
Your business has years of documents, reports, emails, and content AI could use. A knowledge base connects it. Two examples showing what that unlocks.
Your business has already produced what AI needs to work well for you. You just haven’t connected them yet.
Every proposal you’ve written, every report you’ve produced, every email campaign, newsletter, presentation, spreadsheet, and process document – that’s your organizational data. It represents years of decisions, expertise, and accumulated knowledge about your business, your customers, and your industry. It exists in your files right now – captured material that’s been waiting for the right use.
A knowledge base is the step that connects that material to AI. You structure the documents, load them into an AI project, and the AI can read across all of it – answering questions, generating content, finding patterns – grounded in what is specifically true about your business rather than the generic middle of every business it has ever encountered.
With that connection, AI knows everything you’ve documented.
That’s the chain: prepared into a base, activated as live source material.
How a Knowledge Base Works
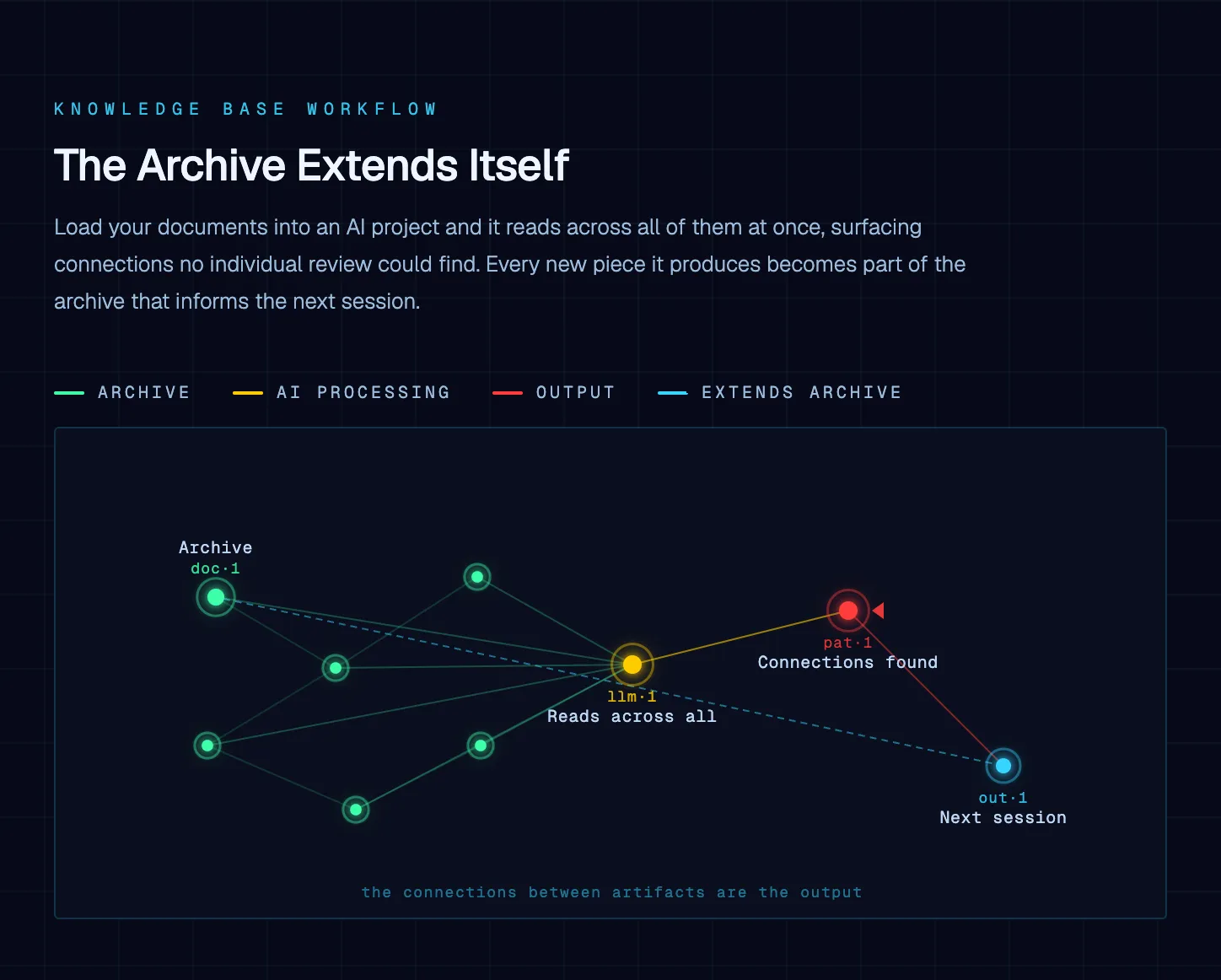
Loading your documents into an AI project works differently from searching them. When you search, you get back documents that contain your keyword. When you load documents into an AI project and ask a question, the AI reads across all of them, understands the relationships between ideas, and returns what is actually relevant – including material that never uses the exact words in your question.
The practical difference: if you want to know which of your hundreds of newsletters best supports a specific concept in a course you’re building, a search returns newsletters that contain the keyword. An AI project returns the newsletters that actually develop the underlying idea – whether or not they use the term you searched for.
The knowledge base is also built from the materials your business generates. Proposals. Client reports. Past email campaigns. Blog posts. Training documents. Meeting transcripts. The more of it you load, the more connections the AI can draw from. The archive you already have is the starting point.
Two Examples
Online Course Creation: Mining Hundreds of Newsletters for a Curriculum
An organization was developing a nine-video online course. Each video covered a distinct topic – the sequence built a conceptual framework from the ground up. The organization had hundreds of newsletters covering the course ideas from multiple angles, written over multiple years.
The question was which specific pieces would serve each video best – and how to sequence supplemental reading alongside the videos to build understanding progressively.
The knowledge base was loaded with the full newsletter archive alongside a foundational blog post. The task: for each of the nine videos, identify three newsletters that best complemented the video’s content, explain why each was the right choice, and describe how the three formed a learning sequence that moved from foundational to applied to conceptual.
What came back was a designed reading curriculum – specific document references, two-to-three sentence justifications grounded in the relationship between each piece and the video’s argument, and an explicit description of how the three progressed together.
One additional finding: a single concept threaded through multiple videos in ways that weren’t fully explicit in the course outline. The knowledge base identified it – finding documents that addressed the same underlying idea from different angles, none of which had been written with the course in mind. The curriculum became more coherent because of it.
Blog Posts: Building New Content from the Archive’s Own Language
A second organization maintained over 100 blog posts on their website – each written in a defined voice and structure. Adding new posts required writing in that voice, matching that structure, and grounding the content in how key ideas had actually been used and developed across the body of work.
The process for developing a new post used the knowledge base in three steps.
First, the transcripts from online presentations and workshops where the topic had come up were searched for every relevant passage – exact context, exact phrasing, the way the idea was introduced and developed in conversation. Second, the existing blog posts where the topic appeared were searched the same way – pulling relevant sections verbatim, with source attribution, preserving the original language. Third, both sets of material went into a session alongside ten existing posts as style reference. The new post was drafted from the extracted material, in the established voice, matching the established structure.
The result: a post that read like every other post on the site – because it was built from the same body of work that produced them. The archive generated new content from itself.
The same pipeline works for any content that needs to feel native to an established body of work. The archive is the brief. The new piece extends it.
What Both Examples Share
The knowledge base makes the archive queryable. Both organizations had the source material before loading it. What changed was the ability to work across all of it simultaneously – to produce specific, grounded recommendations rather than browsing manually for something that might be relevant.
Depth produces connections that aren’t visible in any single document. The course curriculum session found a conceptual thread running through multiple videos that wasn’t visible in the outline. It only appeared when the full archive was in view. That is what an activated knowledge base produces that no individual document review can.
New content built from the archive extends the archive. Every new post produced through the pipeline becomes part of the reference material for the next one. The knowledge base compounds – each addition makes the next session more informed than the last.
Related Reading
The format your documents are in before they go into the knowledge base determines how well the AI can read them – best file format for ChatGPT covers the preparation step that makes an archive actually workable.
A loaded knowledge base is what makes data analysis go beyond what any individual could find manually – ChatGPT for data analysis covers what becomes possible when AI can read across your full body of work.
Content repurposing runs on the same principle – ChatGPT for content creation shows how an activated archive produces content actively.
Want to See This in Your Business?
Book a 30-minute AI Discovery Call where we audit the documents, reports, and content your business has already produced – and show you what an activated knowledge base looks like. No deck, no pitch, no obligation.